




























ABC of Application Architecting on AWS – Series – Part C: (Data)Storage

![]() This blog post is the third and final in a series of three posts on setting up your own application infrastructure on AWS. The three encompass Networks, Computing, and Storage in the respective order. This post is about Storage and there’s a dedicated chapter for each building block and a ton of other useful information!
This blog post is the third and final in a series of three posts on setting up your own application infrastructure on AWS. The three encompass Networks, Computing, and Storage in the respective order. This post is about Storage and there’s a dedicated chapter for each building block and a ton of other useful information!
The AWS building blocks you will learn after having read this post:
Elastic Block Storage (EBS), Elastic File System (EFS), “Simple Storage Service” (S3), Relational Database Service (RDS), ElastiCache, and DynamoDB.
What is this post about?
This post skims through the most common AWS services used to store data, from disk drives attached to EC2 instances, to a globally synchronized milliseconds latency kv-store service. This’ll also try to cover their main features as well as indicate what they’re suitable for.
Hopefully this’ll be helpful in choosing the right storage solution(s) for your application.
Parts of AWS Data Storage block by block
Elastic Block Storage
Elastic Block Storage (EBS) is comparable to a drive used in PCs (either SSD or HDD). They’re attached to an EC2 Instance, and they physically reside in the same Availability Zone as the EC2 instance.
A feature worth mentioning is EBS’ capability to create snapshots: This allows creating a point-in-time backup of the file system (in that specific volume). Those snapshots can then be applied on a new volume, and the new volume attached to the EC2 instance in order to perform a point-in-time recovery. [1]

Using the analogy of EC2 instance <=> PC, EBS is like a disk drive of an instance.
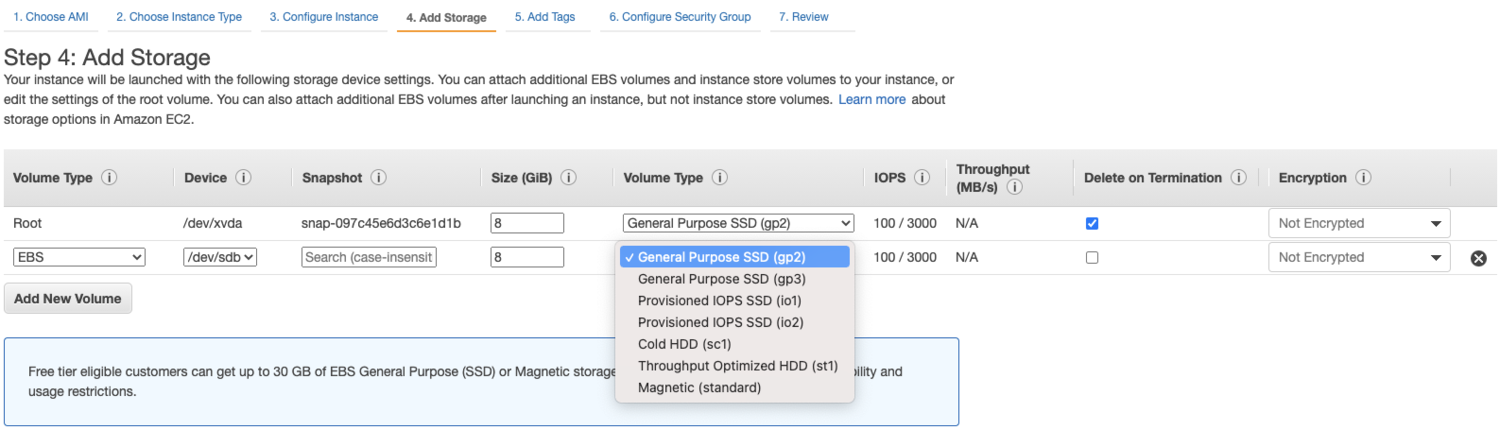
When configuring EBS storage for a new EC2 instance, multiple options are available including both general purpose (“gp”) SSD and low-cost HDD.
Elastic File System
Elastic File System (EFS) is similar to EBS in that it provides a file system with storage capacity, but that can be shared across multiple EC2 instances within the region (regardless of their Availability Zone). Instances connect to the EFS volume through network (using NFSv4 [2]), and nowadays even AWS Lambda supports using EFS volumes from specific lambda functions. [3]
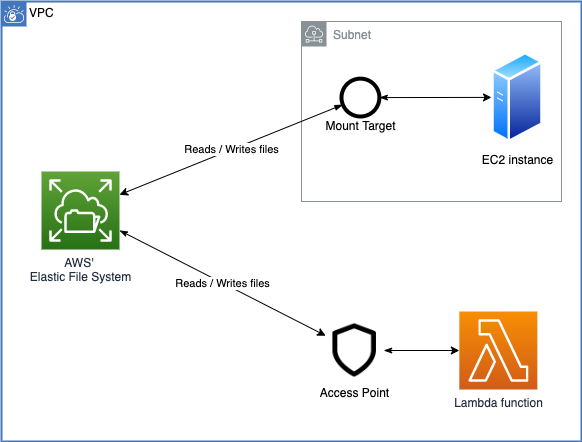
Using EFS, multiple instances (including lambdas) can share datasets and contribute to them.
The downside to EFS is its pricing. [4] [5] It’s many times the price of EBS, but this makes sense considering that many instances (and even lambdas) may share the file system. In an architecture where many instances use shared datasets, it may be cost-effective.
Creating an EFS-volume, then setting up a mount target for it within a subnet, and finally mounting the volume, can be an arduous process. [6] Thankfully though, Infrastructure-as-Code tool like Terraform makes it more straightforward and repeatable. [7] [8]
A good alternative to EFS (depending on use-cases) is S3, which is covered next!
Simple Storage Service
Simple Storage Service (also known as S3) is similar to EFS in that it’s used to store files. However, instead of consisting of a file system, it consists of endlessly expandable (ie. you don’t define a size/capacity) directories called “buckets”. Also unlike EFS, it is accessed using HTTP requests so there is some overhead, and in comparison, EFS does provide lower latency access. This also means S3 bucket(s) are accessed through the internet, and permissions are based on AWS’ Identity and Access Management (via HTTP headers) – unlike EFS’ NFS mounting.
In order to upload an object (file) to S3, a bucket must be created. The bucket is region-specific, however, bucket names are global (referring to s3://my-bucket-123 refers to the specific bucket in a specific region – and that name cannot be used on other regions unless the bucket is deleted). After a bucket is created, objects can be uploaded (and consecutively fetched and deleted) using respective PUT, GET, DELETE requests on S3’s HTTP API from anywhere in the world. AWS’ command-line tool (AWS-CLI) as well as their libraries (AWS-SDK) all use this same RESTful HTTP API under the hood. Objects may be between 0 bytes and 5 terabytes, although large objects must be uploaded using S3 Multipart API. [9]
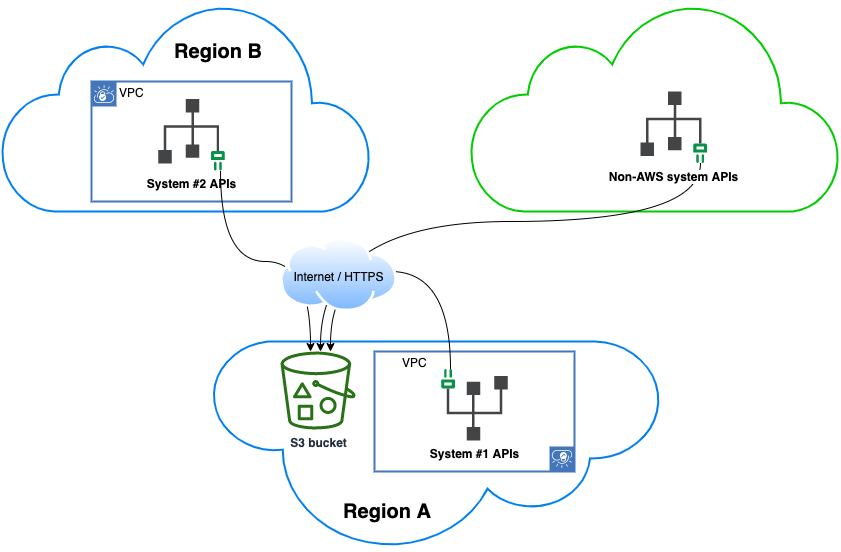
S3 buckets are accessible through the internet, so they’re a favoured method exposing datasets across multiple systems (even to/from non-AWS systems). Access control is performed via HTTP headers (allowed users defined in bucket owner’s AWS account).
When uploading an object to S3 bucket, it may include prefixes (“/” slash delimited strings). While objects are stored in the bucket side-by-side (there’ no “folders”), it may use these prefixes to organize objects just like folders are often used for. Prefixes however are part of object’s “key” (identifier within bucket), and two objects sharing same prefixes (e.g. /photos/2021/img1.jpg and /photos/2021/img2.jpg) may have totally different access rights and other properties. Prefixes themselves don’t have any properties, but they can be used in the same way as tags, for example with a lifecycle rule “delete any over a year old objects with the prefix /photos”.
S3 buckets have a lot of additional options such as
- storage tiers (“more expensive per read/write operation, less expensive /GB storage”)
- lifecycle rules (“perform on objects in the bucket”)
- Access Control Lists (“allow access to specific or all objects in the bucket”)
- API features, such as programmatic creation of “signed URLs” (allowing temporary access to an object for anyone with the special URL)
Going through all of these options would be worthwhile a separate post, but the bottom line is that S3 allows more flexibility (than EFS) when the data is to be shared outside VPC’s network. S3 also scales indefinitely, so costs (per API request and per /GB stored) must be tracked (and unnecessary files removed either using lifecycle rules or manually).
Additionally there’ S3-specific tools that AWS provides such as AWS Athena (a service for making SQL queries on JSON, CSV, or other columnar files in S3 buckets), and AWS Macie (a service using machine learning that scans S3 buckets for security issues and any sensitive information such as Personally Identifiable Information, and generates reports for you).
Relational Database Service
Relational Database Service (RDS) is basically an EC2 instance with a pre-installed relational database, that AWS keeps up-to-date for you and performs any other maintenance (guaranteeing uptime with their service level agreement).
Familiar relational database engines such as MySQL and PostgreSQL are available, as well as more optimized AWS’ Aurora engine. When setting up a new RDS service (cluster or instance), you have many similar options as when creating a new EC2 instance (EC2 instance class, storage type, size of allocated storage) as well as database related options (database engine, engine version, root user credentials, etc.). [10] [11]
Running an RDS instance is generally more expensive than running an equivalent EC2 instance (that can have the same storage, same relational database software running), however, the automated maintenance, convenient re-scaling (creation of read replica instances), and support that is available (in case of any issues) are generally worthwhile to use RDS instead.
Nowadays there exists also a serverless (cluster-only) engine, which is good for infrequent database usage (pay per use). It works similarly to AWS Lambda in that it scales up/down based on usage, and there’s a delay when it hasn’t been used in a while, but otherwise can be used as a normal MySQL/PostgreSQL-compatible database instance. It does come with some AWS-specific limitations such as the inability to export snapshots to S3, one should check these before choosing to use Serverless RDS. [12]
ElastiCache
ElastiCache is a hosted version of a popular open-source in-memory data store (either Redis or Memcached, chosen when setting up). [13] You can find detailed information on those software systems elsewhere, but the point of AWS’ ElastiCache is similar to RDS: While you could set up an EC2 instance where you install (and maintain yourself) either Redis or Memcached, using ElastiCache you let AWS keep it up-to-date and maintain it when necessary. Also creating replicas from ElastiCache is more convenient than with a DIY solution.
DynamoDB
DynamoDB provides a key-value store, accessed using HTTP API from anywhere in the world. The main benefit of DynamoDB is extremely low (milliseconds) latency for same-region access, allowing very rapid reading and writing of key-value combinations for distributed applications.
DynamoDB is made up of “tables”, and tables can be either region-specific or global (with data written to one region replicated to other regions measured by ReplicationLatency). [14] [15] Tables (regional or global) have a specified “Partition Key” which is the unique identifier (“key”) for either a single of multiple items (“values”) in that table. When querying for item(s), a partition key must always be provided so it’s the most important decision when defining a schema for DynamoDB. [16]
In addition to a partition key, a sort key can be specified, creating together a “composite primary key” that’s used to find item(s) in DynamoDB. Something to keep in mind is that querying still requires a partition key before the sort key, so doing SQL-like queries with a sort key is impossible (and this may backfire later on if the DynamoDB table was badly designed). Sort key should be considered as an additional filter to items contained within a partition key. [16]
Because of all these gotchas, DynamoDB has (and its two alternative pricing models – more expensive on-demand – and less expensive possibly throttled provisioned capacity) one should really plan ahead whether DynamoDB suits the needs of architecture. It can be mind-blowingly fast and great when it can be used, but unlike relational databases where the schema is based on entity relationships and data normalization - in DynamoDB schema must be designed based on use-cases. Otherwise, it may become both slow and expensive (ending up in excessive use of “scan” operations and on-demand tables). [17]
Notes
- EBS and EFS provide file systems for EC2 instances. EBS by connecting it to an EC2 instance within the same Availability Zone. EFS to multiple instances using NFSv4.
- S3 provides regional file storage (organized using prefixes) for files of varying sizes (from 0B to 5TB), that can be flexibly shared between applications and third parties (even publicly).
- RDS is equivalent to AWS-maintained EC2 instance(s) running a relational database of your choice.
- ElastiCache is equivalent to AWS-maintained EC2 instance(s) running Redis or Memcached.
- DynamoDB provides regional (optionally globally replicated) key-value storage for specific high throughput low-latency use cases.
References
1 Replace an Amazon EBS volume (docs.aws.amazon.com)
2 Amazon Elastic File System: How it works (docs.aws.amazon.com)
3 Using Amazon EFS for AWS Lambda in your serverless applications (aws.amazon.com)
4 Amazon EBS pricing (aws.amazon.com)
5 Amazon EFS pricing (aws.amazon.com)
6 Walkthrough: Create and Mount a File System Using the AWS CLI (docs.aws.amazon.com)
7 https://registry.terraform.io/providers/hashicorp/aws/latest/docs/resources/efs_file_system
8 https://registry.terraform.io/providers/hashicorp/aws/latest/docs/resources/efs_mount_target
9 Amazon S3 – Object Size Limit Now 5 TB (aws.amazon.com)
10 https://registry.terraform.io/providers/hashicorp/aws/latest/docs/resources/rds_cluster
11 https://registry.terraform.io/providers/hashicorp/aws/latest/docs/resources/db_instance
12 Using Amazon Aurora Serverless v1 (docs.aws.amazon.com)
13 Comparing Redis and Memcached (aws.amazon.com)
14 Global Tables: Multi-Region Replication with DynamoDB (docs.aws.amazon.com)
15 Monitoring Global Tables (docs.aws.amazon.com)
16 Choosing the Right DynamoDB Partition Key (aws.amazon.com)
17 Amazon DynamoDB pricing (aws.amazon.com)
This concludes the three-part blog series on setting up your own application infrastructure on AWS. To wrap up this series of posts, I truly wish it did any good or assisted you in getting started with the daunting jungle that is Amazon Web Services. ????
Read the other parts of the series here:
ABC of Application Architecting on AWS – Series – Part A: Networks
ABC of Application Architecting on AWS – Series – Part B: Computing
















 Kaikki it-alan tapahtumat »
Kaikki it-alan tapahtumat »













