




























Palava palvelin ja muita toipumisen aiheita – miten Azure kestää?

![]() Kuinka turvassa datani olisi, jos Azuren datakeskus palaisi? Mikä on Availability Zone, ja pitäisikö minun välittää siitä? Tämä artikkeli kertaa perustiedot Azuren kahdennus- ja toipumisjärjestelyistä.
Kuinka turvassa datani olisi, jos Azuren datakeskus palaisi? Mikä on Availability Zone, ja pitäisikö minun välittää siitä? Tämä artikkeli kertaa perustiedot Azuren kahdennus- ja toipumisjärjestelyistä.
Ranskalaisen kapasiteetintarjoaja OVH:n datakeskuspalo maaliskuun puolivälissä häiritsi miljoonia verkkopalveluita. Ilmeisesti UPS-laitteen virtalähteestä alkunsa saanut palo tuhosi n. 15 000 palvelinta ja kaiken niillä olleen datan. Rakennus tuhoutui täysin, ja palveluntarjoajan suositus oli viileä: ”Aktivoikaa toipumissuunnitelmanne”. Oheisella videolla näkyy Strasbourgin datakeskuksen tulipalo – ensin ilmiliekeissä, sitten sammutusvaiheessa.
Voisiko sama toistua Azuressa?
Hurjan näköinen tapahtuma havahdutti monet tietohallintopäättäjät miettimään sitä, voisiko sama tapahtua itselle, ja varmasti useampi konesalipalveluntarjoaja sai huolestuneita soittoja asiakkailtaan. Mutta entä jos käytät jo julkista pilveä – voisiko tämä tapahtua sinulle?
On houkuttelevaa ajatella, että palvelinkeskuksen palaminen on ongelma, joka ei voi maailmanluokan julkipilvessä toistua. Microsoftin, Amazonin ja Googlen kaltaisten palveluntarjoajien pilvisalit ovat teknisesti huippulaatua, ja palon leviäminen koko rakennukseen tuntuu epätodennäköiseltä. Toisaalta OVH:kaan ei ole mikään Hikiän Hermannin Hostaamo, vaan 600 miljoonan euron liikevaihtoa tekevä pitkän linjan palveluyritys, jolla on 27 datakeskusta ympäri maailman.
Samat uhat tuskin toistuisivat sellaisenaan Microsoftin palvelinkeskuksissa, mutta tokkopa Azure-palvelimetkaan palamatonta ainetta ovat. Ja vaikka liekeistä ajattelisi mitä, ainahan Airbus voi laskeutua hallitsemattomasti datakeskuksen päälle. Täysin ei voine sulkea pois myöskään terrorismin kaltaisia ulkoisia tekijöitä. Mitä kauhukuvia sitten ajatteleekin, Microsoftin huolellisuus ei korvaa omaa, mietittyä ja testattua toipumissuunnitelmaa. Todennäköisyys sen tarvitsemiselle on pieni, mutta onko se riittävän pieni, jotta suunnittelun voisi jättää tekemättä?
Pikakurssi Azuren infran rakenteeseen
Azuren käyttöönotossa katastrofisuunnittelu ei ole päällimmäisenä mielessä. Suurin osa palveluista – varsinkin PaaS-puolella – syntyy ilman minkäänlaista ajatusta siitä, missä palvelut oikeastaan pyörivät tai miten. Uutta Azure-resurssia luodessaan käyttäjä valitsee tyypillisesti vain sen, mihin regioniin palvelu lisätään. Mutta harva ajattelee sitäkään, mitä konkreettisesti tarkoittaa ”region” – eli missä palveluni oikeastaan ovat, jos ne ovat ”West Europessa”?
Kuten alla olevasta kaaviokuvasta näkyy, regionin sisältä löytyy vielä zoneja, ja vasta zonejen alta päästään konkreettisiin datacentereihin – siis rakennuksiin, joiden sisällä on prosessoreita, levyjä ja verkkokortteja. Mutta mitä nämä kaikki rakenteet ovat?
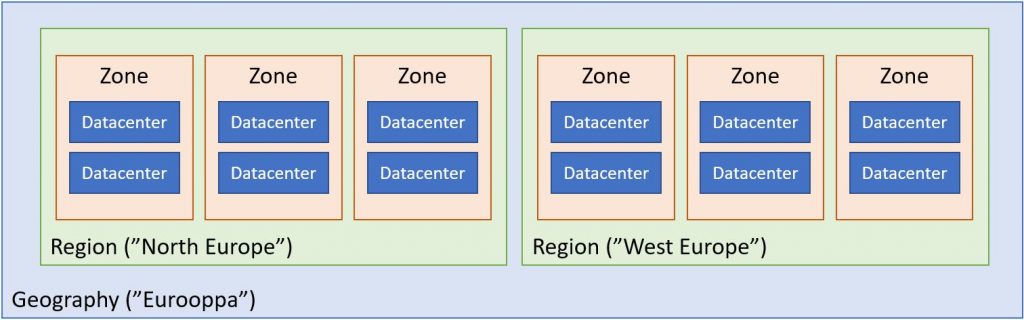
Useimmissa isoissa Azuren regioneissa on käytössä niin sanottu Availability Zones -jako, ja Microsoft on asettanut julkiseksi tavoitteeksi sen, että vuoden 2021 loppuun mennessä kaikissa regioneissa on vähintään kolme zonea. Suomalaisten kannalta tärkeimmät West ja North Europe tukevat molemmat kolmea zonea jo nyt.
Mikä zone sitten on? Zone tarkoittaa joukkoa datakeskuksia, joilla on yhteinen keskeinen infrastruktuuri – käytännössä sähköjärjestelmä, jäähdytys ja verkkoyhteys. Regionin muodostavat zonet on yhdistetty dedikoidulla kuituverkolla ja sijoiteltu siten, että niihin liittyisi mahdollisimman vähän yhteisiä riskejä. Suunnittelussa voidaan tavoitella esim. erillisiä sähkön ja jäähdytyksen lähteitä ja sopivaa fyysistä etäisyyttä.
Kovin kauas toisistaan niitä ei voi kuitenkaan laittaa, sillä region-tason verkkosynkronoinnin takia palveluiden fyysinen matka ei saa kasvaa kovin suureksi: lopulta valokin on aika hidasta. Sopiva yksinkertaistus voisi olla esimerkiksi se, että yhden regionin zonet ovat saman kaupungin eri puolilla. Täsmällisiä sijainteja ei tietenkään ole missään julkaistu.
Regionit taas puolestaan pyritään sijoittamaan riittävän kauas toisistaan – Microsoftin tavoite on vähintään 300 mailia – jotta poliittiset ja maantieteelliset riskit eivät todennäköisesti koskettaisi useampaa regionia yhtäaikaisesti.
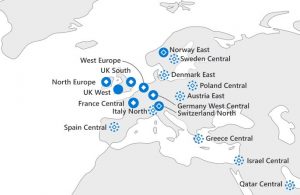
Geography-käsite kattaa useamman regionin, ja tarkoittaa yleensä yhtä maantieteellisesti mielekästä hallinnollista aluetta, jonka sisällä katastrofitilanteen failover on asiakkaille tarkoituksenmukainen. Esimerkki tällaisesta alueesta on siis Eurooppa, jossa on yksi region-pari (West ja North Europe – käytännössä Amsterdam ja Dublin). Aluerajauksen takia pahimman katastrofinkaan aikana data ei poistu Euroopan talousalueelta.
Region-pareilla ei ole mitään jokapäiväistä merkitystä asiakkaille, mutta Microsoftin hallintaprosessit on suunniteltu siten, että katastrofin sattuessa optimaalinen toipumiskokemus saadaan, jos palvelut on hajautettu tämän parin kesken. Region-parit on lueteltu Azuren dokumentaatiossa, ja samalla sivulla käsitellään myös parien toimintaa tarkemmin.
No, miten ne palvelut oikeasti toimivat?
Pelkkä infrastruktuuritietämys ei auta resilienssin suunnittelussa. Seuraava tärkeä kysymys on se, miten mikäkin Azuren palvelu osaa hyödyntää tätä infrastruktuuria. Ja tässä suhteessa palvelut poikkeavatkin toisistaan varsin paljon.

Ensinnäkin on olemassa joukko globaaleja palveluita, joiden sijaintia ei voi edes valita, vaan ne tarjoillaan aina globaalisti. Tällaisia ovat esimerkiksi Azure Active Directory, Azure DNS, Azure Bot Services ja joukko muita. Koko luettelo palveluiden hajautustuesta löytyy Azuren dokumentaatiosta.
Yksittäiselle regionille asennettavat palvelut jakautuvat kolmeen kategoriaan: niihin, jotka asennetaan nimenomaisesti yksittäiseen zoneen (Azuren termein zonal services), niihin, jotka automaattisesti replikoituvat useampiin saman regionin zoneihin (zone-redundant services) ja muihin – käytännössä niihin, jotka asentuvat käyttäjältä näkymättömästi vain johonkin yksittäiseen zoneen.
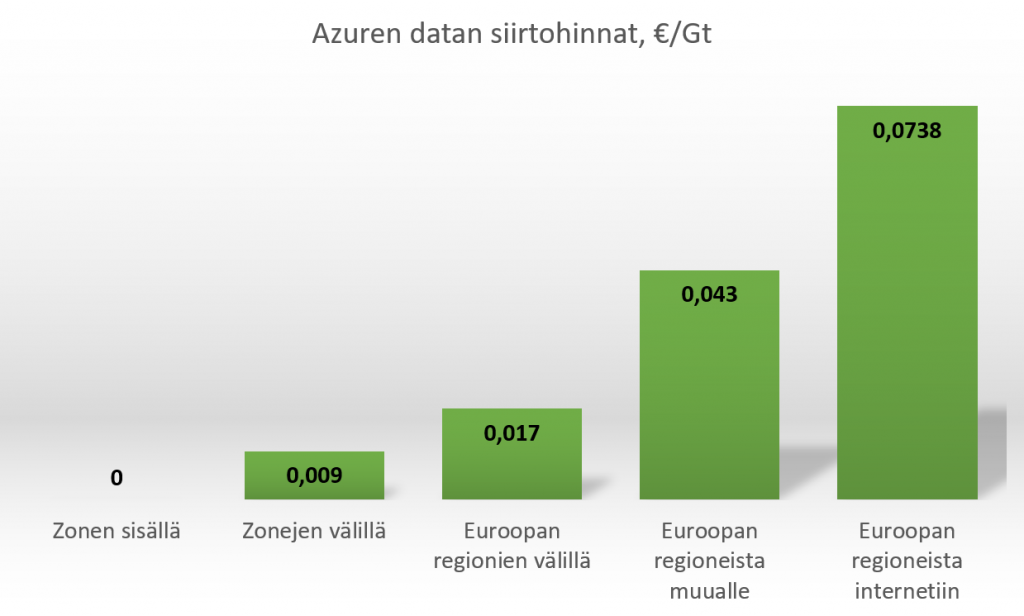
Esimerkkejä zonal services -ajattelusta löytyy IaaS-puolelta. Esimerkiksi virtuaalikonetta luodessa voi suoraan valita, mihin zoneen (1-3) koneen laittaa. Mikään näistä valinnoista ei ole toista parempi, joten valinta on puhtaasti looginen: alimman mahdollisen latenssin saavuttamiseksi kannattaa ryhmitellä IaaS-resurssit yhteen zoneen, ja toisaalta parhaan resilienssin saa luomalla virtuaalikoneklusterin, jonka kaikki noodit ovat eri zoneilla. Hyvä on huomata sekin, että siinä missä verkkoliikenne zonen sisällä on ilmaista, zonejen välillä se maksaa – tosin vain n. 12 % siitä mitä internetiin suuntautuva liikenne.
Storage Accountin luonnin yhteydessä valinnan saa tehdä kaikkein monipuolisimmin. Valintadialogista voi suoraan valita, haluaako tiedot replikoida vain paikallisen datakeskuksen sisällä (LRS), zone-tason katastrofin kestävästi koko regionin sisällä (ZRS) tai peräti toiselle regionille (GRS). Laajalla replikoinnilla voi tuplata datavarastoinnin hinnan, mutta ei se toisaalta kovin kallista silloinkaan ole.

PaaS-puolella zone-kohdistuksia ei pääse tekemään. Tällöin kyse onkin siitä, mitkä palvelut tukevat zoneja ja regioneja ylipäätään. Tätä vastausta on lähdettävä hakemaan Azuren dokumentaation zone-tukiluettelosta, joka on valitettavasti melko niukkasanainen tuen täsmällisestä sisällöstä. Suuri osa tavallisimmista palveluista on toteutettu siten, että ne ovat sisäisesti ”zone-hajautettuja” – eli että regionin yksittäisen zonen halvaantuminen ei vielä kaada palvelua. Toisaalta tulkinta vaatii huomattavasti tarkkuutta: esimerkiksi Cosmos DB tukee zone-hajautusta, mutta vain, jos sen kytkee erikseen päälle – ja maksaa siitä 25 % lisähinnan.
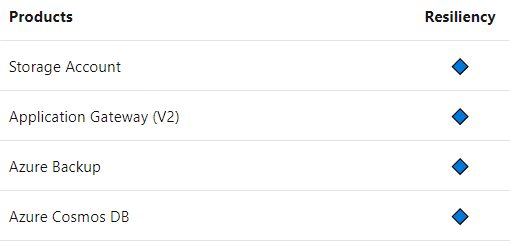
Zone-hajautettujen palveluiden listassa on kuitenkin puutteita. Esimerkiksi varsin usein käytetyt Azure App Service ja Azure API Management perusmuodoissaan asettuvat aina vain yhdelle zonelle. Toisaalta Microsoft on sitoutunut lisäämään zone-tason redundanssin Azuren tavallisimpiin palveluihin vuoden 2021 aikana, joten tilanne on näiltä osin paranemassa. Tiedot kannattaa kuitenkin aina tarkistaa kyseisen Azure-palvelun dokumentaatiosta – muutos on sen verran nopeaa, että tämänkin kirjoituksen yksityiskohdat happanevat viikoissa.
Neljä neuvoa jatkuvuussuunnitteluun
Datakeskuskatastrofeista keskustelu on ahdistavaa, ja kattava analyysi parhaista ratkaisuvaihtoehdoista vaatii tapauskohtaista perehtymistä. Paniikkiin ei ole syytä: yksikin Azuren zone on todennäköisesti luotettavuudeltaan paras ympäristö, jossa palvelusi ovat ikinä pyörineet. Silti OVH:n tapaus muistutti taas, että huolellisuuteen on aihetta. Seuraavien askelten kautta voi lähteä etsimään omalle organisaatiolle ja palvelupaletille optimaalista tasapainoa.
#1: Kartoita datan kriittisyys
Azure varastoi kaiken datan aina vähintään LRS-tasoisena (kolme kopiota saman palvelinkeskuksen sisällä), ja lupaa sille 99,999999999 % säilyvyyden vuodessa – siis 11 ysiä. Tämä on useimmissa tilanteissa täysin riittävää. Korkeammilla replikointitasoilla säilyvyyslupaus kasvaa peräti 16 ysiin, mutta ero on toki käytännössä melko pieni. Toisaalta LRS-tason redundanssi saattaa olla altis yksittäistä palvelinkeskusaluetta koskevalle katastrofille, joten ZRS-taso on hyvinkin perusteltu kriittiselle datalle.
Todennäköisemmin laajoissa ongelmatilanteissa kyse on siitä, että miten vakava vaikutus on sillä, jos jokin osa järjestelmistä on pois päältä – ja niiden data saavuttamattomissa – esimerkiksi tunnin tai kaksi. Tai entä, jos katko kestää päivän tai kaksi? Todettakoon, että laajoja tämän tason katkoja ei Azuressa vielä koskaan ole ollut.
#2: Testaa datan toipumiset ja integroinnit
Monet Azuren dataa varastoivista palveluista sisältävät mainiot välineet toipumiseen. Joskus haasteeksi tulee kuitenkin se, että vaikka järjestelmän jokaisen tietovaraston saisikin palautettua yksinään, on vaikea palauttaa monesta osasta koostuva järjestelmä täsmälleen synkronoituun tilaan: aivan kaikki ei ollutkaan transaktionaalista, tai sitten dataa on jäänyt ongelmatilanteen alkaessa jumiin vaikkapa Service Bus -jonoihin, joiden palauttamiseen ei olekaan varauduttu.
Monesti puuttuvaa dataa voidaan korvata ajamalla erilaisia integraatio- ja synkronointiprosesseja uusiksi. Niiden kesto saattaa kuitenkin tulla yllätyksenä: Kaksi tuntia kestänyt Azure-häiriö venyykin viiteen tuntiin, kun datan oikeellisuuden varmistamisen kesto yllättää. Tähän paras lääke on testata erilaiset massasynkronoinnit ajoissa, ja pitää niistä jonkinlaista tietoa yllä. Jos katastrofi iskee, on toipumissuunnittelua helpompi tehdä, jos tiimillä on ainakin tuoreehkot faktat siitä, miten käyttökelpoisia ja nopeita mitkäkin toipumisreitit ovat.
#3: Harkitse data-aineistojen georeplikointia
Kriittisten liiketoiminta-aineistojen osalta kahdentaminen toiselle regionille voi olla hyvin järkevää. Kaikki Azuren tavanomaisimmat tietovarastot – Storage Account, Azure SQL Database ja Cosmos DB – ovat hyvin pienellä vaivalla ja melko kustannustehokkaasti kahdennettavissa toiseen regioniin.
Samalla voi pohtia sitä, olisiko kahdennuksella saatavissa jotain liiketoiminnallista hyötyä katastrofiajan ulkopuolellakin. Suomesta lähtevän liikenteen jakaminen kahdelle Azure-regionille ei ole latenssinäkökulmasta hyödyllistä, mutta globaalisti käytetyn palvelun kohdalla käyttäjäkokemus saattaa parantua, jos toinen datakeskus olisikin lähempänä asiakkaita. Tämä ratkaisu vaatii toki useimmiten myös järjestelmäkehitystä ja siten investointeja, joten hyötyjä kannattaa punnita tarkkaan.
#4: Muista infrastructure-as-code-ajattelu
Edellä on puhuttu paljon datan suojaamisesta, koska sen katoaminen olisikin useimmiten se pahin katastrofi. Toipumissuunnittelussa on kuitenkin hyvä miettiä myös sitä, miten loogisen palveluinfrastruktuurin – siis Azuren tilausten, resurssiryhmien ja resurssien – palauttaminen onnistuisi, jos se olisi jostain syystä tarpeen. Mitä tekisit, jos jonain aamuna Azure-resurssisi olisivat vain kadonneet?
Toivottavasti Azure ei koskaan varsinaisesti hukkaa resurssejasi, mutta kysymys ei silti ole täysin merkityksetön. Jos meteoriitti murskaa Amsterdamista ison kasan tehonäytönohjamilla varustettuja palvelimia, täydellinen toipuminen nykyisen sirupulan aikana kestää, jopa Microsoftin resursseilla. Jos ratkaisusi sattuu vaatimaan juuri tällaista kapasiteettia, voi olla, että nopein tapa toipua on siirtää sovellus pyörimään Irlantiin, Saksaan tai vaikkapa Norjaan.
Tällöin korostuu infrastructure-as-code-praktiikka – eli se, että Azure-resurssit konfiguraatioineen on määritelty ajettavina skripteinä. Tavoite koko ympäristön synnyttämisestä nappia painamalla on monesti epätarkoituksenmukaisen kallis, mutta käsin virkatun ja täydellisesti automatisoidun asennusmallin väliltä löytyy järkeviä kompromisseja. Näitä kannattaa tarkastella ennalta.
Hyvin toteutetun IaC-mallin lisäetuna tulee se, että testiympäristöjen perustaminen helpottuu. Niiden kanssa kannattaakin välillä aloittaa tyhjästä: samallahan tulee testanneeksi myös tiedonpalautussuunnitelmia.
Jouni on 25 vuoden uransa aikana tehnyt kaikkea helpdeskistä henkilöstöjohtamiseen ja koodauksesta kolvaamiseen. Hänen erityisalaansa ovat Microsoft-teknologioiden käyttöönotot, monimutkaiset ongelmat sekä ohjelmistotuotannon laatukysymykset. Jouni on Devisioonan toimitusjohtaja ja yksi maailman 160 Microsoft Regional Directorista.






 Kaikki it-alan tapahtumat »
Kaikki it-alan tapahtumat »













